
우리 회사를 포함해 많은 회사는 RDBMS를 사용할 때 MySQL Amazon Aurora DB(이하 오로라)를 사용하는 경우가 존재한다. 왜 오로라를 사용하는 지 궁금했는데 기존 전통적인 MySQL보다 가용성, 확장성, 연산 비용 등이 더 싸서 대규모 처리 작업에 용이해서 사용한다고 들었다. 또, 오로라는 컴퓨팅과 스토리지 인스턴스가 각각 분리되어 있다. 여기서 오로라 스토리지 엔진이 기존 MySQL 스토리지 엔진인 InnoDB와 큰 차이가 있는지도 궁금했었다.
마침 Real MySQL 스터디에서 MySQL에서 대체로 쓰이는 스토리지 엔진인 InnoDB 스토리지 엔진의 구조에 대해 공부하면서, 영속성을 제공하는 DoubleWrite buffer 기능이 흥미로웠다. 언뜻보면 비효율적으로 보일 수 있는 연산으로 보였기 때문이다. 물론 옵션을 끌 수 있겠지만, 정합성 측면에서 끄는 것을 권장하지 않아 사용한다고 가정했을 때 더 효율적인 방법이 있을 지도 궁금했다. 그렇기에 스토리지 엔진을 개선한 오로라는 어떻게 효율적으로 처리하는 지 알아보자.
Amazon Aurora
오로라같은 경우 기존 전통적인 MySQL에 비해 더 좋은 퍼포먼스, 확장성, 가용성과 내구성을 제공한다. 이는 컴퓨팅과 스토리지 엔진을 분리해서 제공함을 통해 제공하며, 기존 MySQL 엔진과 InnoDB 스토리지 엔진을 커스터마이징해서 Aurora로 제공한다. Aurora Storage 엔진에서 더 좋은 퍼포먼스를 이야기할 때 특히나 I/O 연산 최적화를 다음과 같이 언급한다.
Aurora는 비용을 절감하고 읽기/쓰기 트래픽을 위해 사용할 수 있는 리소스를 확보하기 위해 불필요한 I/O를 제거하도록 설계되었습니다. 쓰기 I/O는 안정적인 쓰기를 위해 트랜잭션 로그 기록을 스토리지 계층으로 푸시할 때만 사용됩니다. (중략) 기존 데이터베이스 엔진과는 달리 Amazon Aurora는 변경된 데이터베이스 페이지를 스토리지 계층으로 푸시하지 않으므로 I/O 사용을 좀 더 줄일 수 있습니다. 링크
트랜잭션 로그 기록을 스토리지 계층으로 푸시한다는 의미는 무엇이고, 기존 InnoDB는 그렇다면 데이터를 스토리지 엔진으로 푸시하는 것일까? 이 두 개의 관점을 비교하면서 알아보자.
InnoDB 스토리지 엔진 구조
InnoDB 스토리지 엔진은 RDBMS에서 말 그대로 스토리지 디스크로부터 데이터를 잘 가져오는 역할을 한다. InnoDB 스토리지 엔진은 트랜잭션, 장애 복구, 락, 백업 등 여러가지 스토리지와 관련된 기능을 제공한다. 공식 문서에 나와있는 아키텍쳐는 다음과 같다.
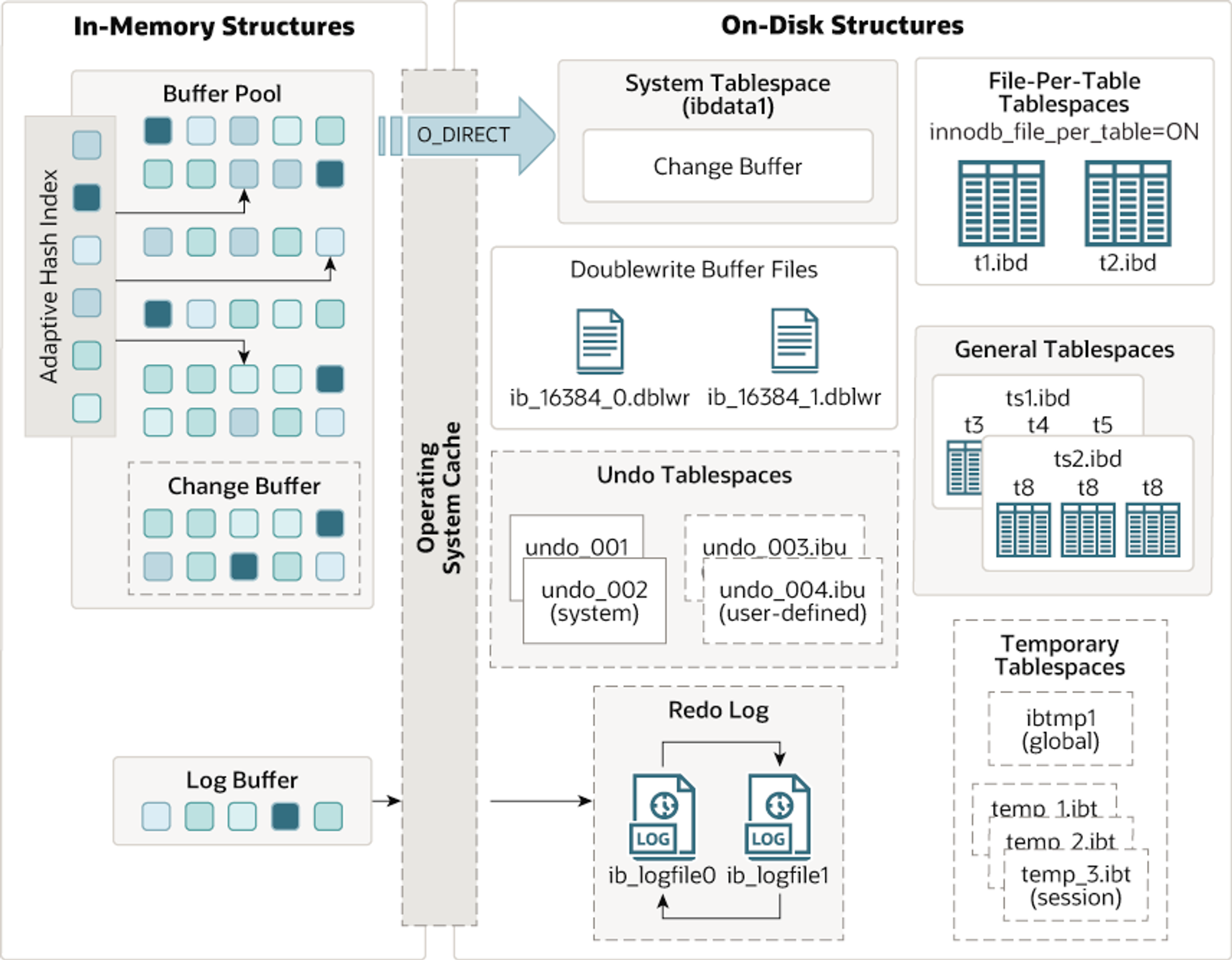
여기서 주의 깊게 봐야할 것은 DoubleWrite Buffer와 Buffer Pool이다. 여러 기능을 제공하지만, 버퍼 풀은 쓰기 지연 작업과 데이터 파일을 캐싱하는 역할을 하며, DoubleWrite Buffer는 데이터 정합성을 위해 버퍼풀에서 데이터 파일에 쓰기 작업을 하기 직전에 디스크에 따로 작성하는 로그이다.
MySQL Doublewrite buffer
innodb의 버퍼 풀에서는 기본적으로 데이터 파일에 flush하기 전에 doublewrite buffer를 스토리지에 저장한다. 이는 데이터의 무결성을 위함으로, 버퍼 풀에서 데이터 파일로 쓰기 작업 실패가 발생할 때를 사용된다. 실패가 나게 되면, doublewrite buffer의 내용과 데이터 파일을 비교해서 다른 내용을 담고 있는 페이지가 존재하면 doublewrite buffer의 내용을 데이터 파일의 페이지로 복사하게 된다. 이를 통해 시스템의 비정상적 종료에도 무결성을 보장할 수 있게된다.
예를 들어 다음 그림에서 innodb 버퍼 풀에서 데이터 파일에 쓰기 전에 먼저 DoubleWrite Buffer에 페이지를 작성하게 된다. 그 이후 버퍼 풀에서 flush를 진행해 데이터 파일에 쓰기를 진행한다. 만약 여기서 C 데이터 파일에 쓰는 과정에서 MySQL 서버가 종료되었다고 하면, 재시작할 때 forcing recovery로 인해 Doublewrite buffer의 내용이 해당 데이터 파일로 쓰기 작업이 일어난다.이를 통해 데이터 무결성을 보장할 수 있게된다.
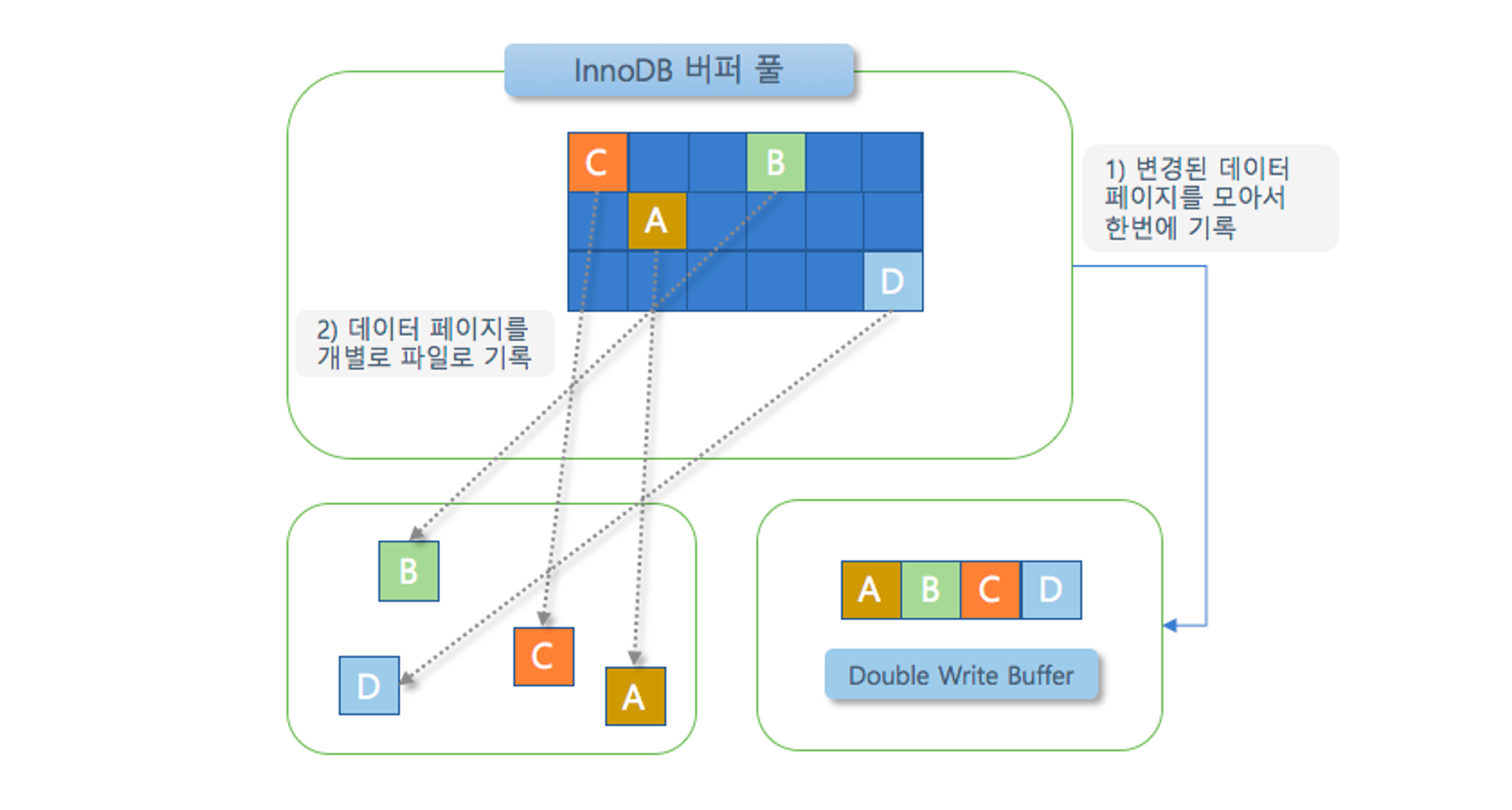
Doublewrite buffer 작업은 디스크에 실질적으로 쓰기 작업을 두 번 진행하는 것으로 볼 수 있다. 이에 대해 공식 문서에서는 2번의 쓰기 작업 I/O가 발생하지만 오버헤드는 2번 만큼 발생하지 않는다고 언급했다. 하지만 오로라는 이 Doublewrite buffer를 배제하는 방법으로 쓰기 작업을 진행한다. 즉, Doublewrite buffer를 작업하지 않으기에 표면적으로 봤을 떄 연산이 더 적다고 볼 수 있다.
Amazon Aurora의 쓰기 연산 작업
다음 그림에서 볼 수 있듯이, insert를 진행할 때 MySQL은 doublewrite buffer과 Datafile에 쓰기 작업을 진행하지만, Aurora 같은 경우에는 스토리지에 로그를 쌓는 것이 전부이다. 그 이후의 작업은 오로라 스토리지 내부적으로 작업을 진행하게 된다.
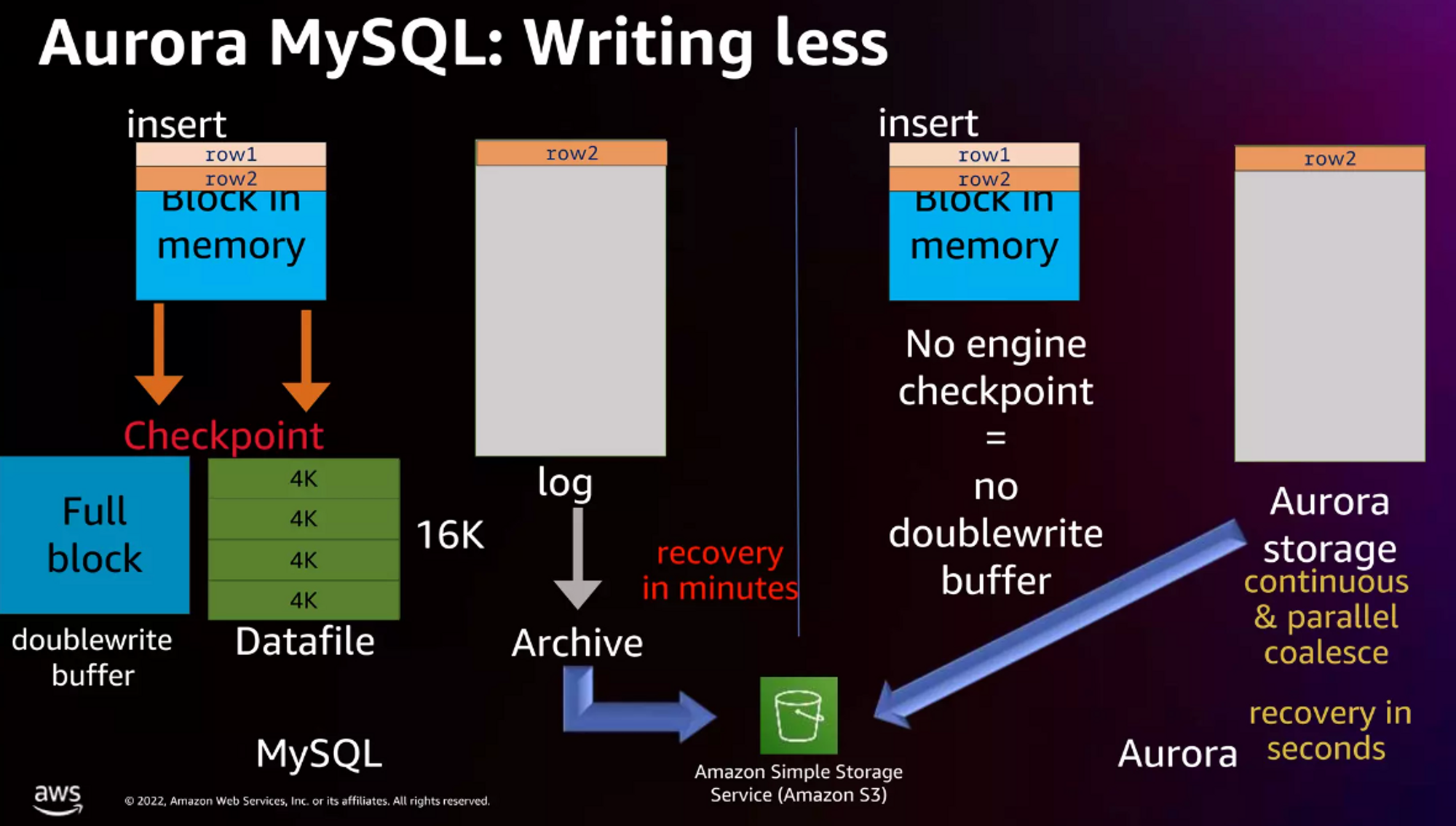
Aurora같은 경우에는 스토리지 구조가 log-structured storage이다. 위 그림에서 볼 수 있듯 오로라 스토리지에 로그만 쌓고 쓰기 작업이 끝난다. 그렇기에 오로라의 스토리지 쓰기 작업은 위에서 인용구에서 언급했듯, 트랜잭션 로그 기록(리두 로그)을 스토리지 계층으로 푸시할 때만 쓰기 I/O가 발생한다. 그렇기에 DoubleWrite buffer가 없을 뿐더러 데이터 파일도 직접 쓰기 연산을 하지 않는다. 이는 리두 로그(WAL)만을 디스크에 쓰기 연산함으로 I/O 연산을 극단적으로 줄일 수 있다. 또, 로그 파일은 데이터 파일에 비해 상대적으로 데이터 크기가 작을 것이기 때문에 실질적으로 더 많은 데이터 파일을 적은 I/O로 쓸 수 있게 되는 것이다.
언뜻 생각해보면 MySQL에서 리두 로그(WAL)를 모두 쌓지 않는 이유는 로그를 모두 쌓아서 연산함으로 데이터를 기록하게 되면 디스크 연산이 많아져 너무 느려져서라고 생각했었다. 하지만 오로라는 이를 Log Stream과 병렬 연산을 통해 연산 속도 문제를 해결했으며 그 관련 구조는 다음과 같다.
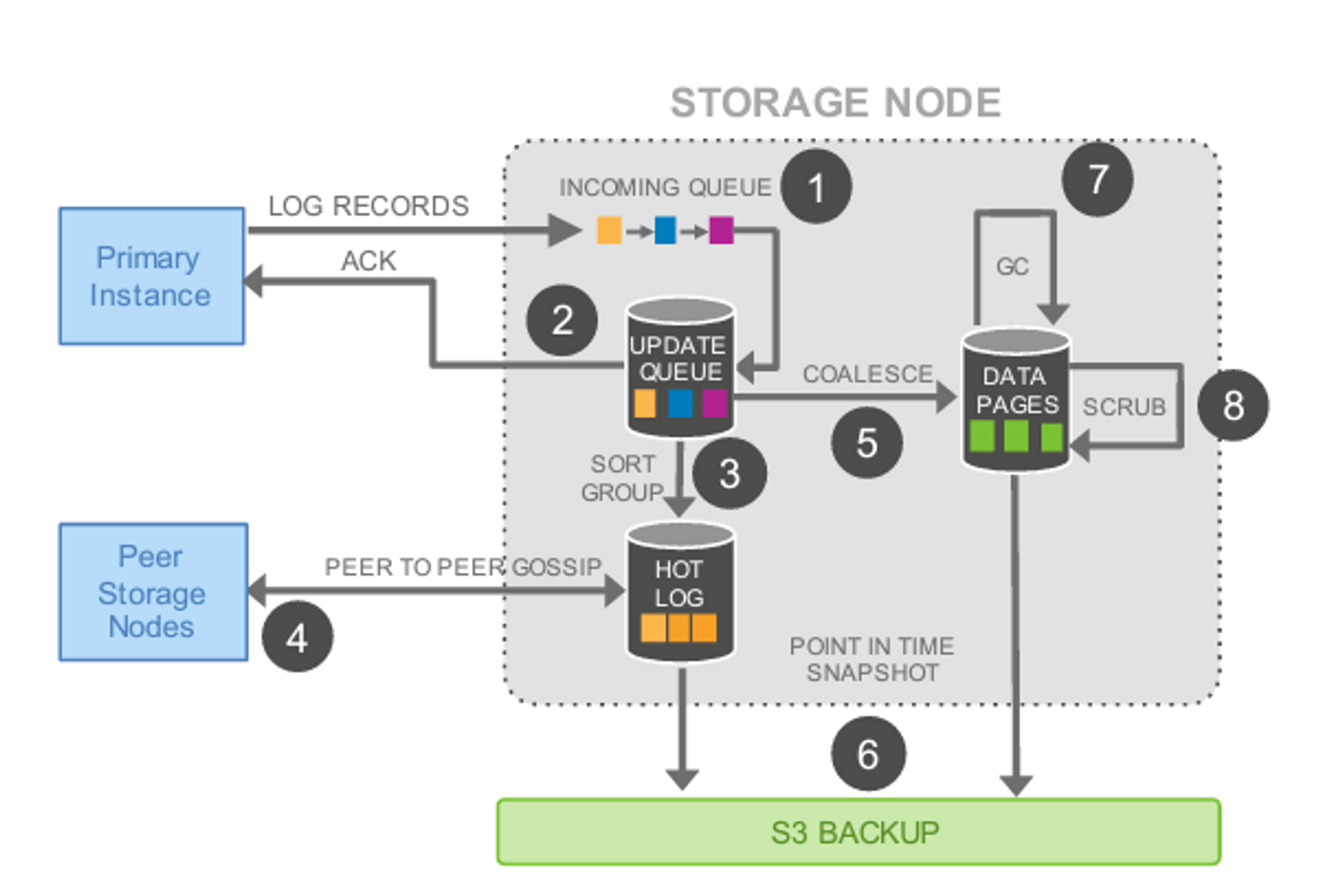
글에 요지에 벗어나서 구체적으로 다루지는 않지만, 로그 데이터를 incoming queue에서 받아 update queue로 동기식으로 전달하고 그 이후는 비동기 및 병렬로 처리해 데이터 파일에 쓰기 작업이 일어나게 된다. 또, 이렇게 작업된 것들은 S3에 저장함으로 손쉽게 백업을 구현한다. 이를 통해 오로라가 I/O를 기존 RDS MySQL에 비해 더 좋은 성능을 낼 수 있게 되었다.
디스크 I/O는 상대적으로 비싼 작업인 만큼 이는 수백, 수천만 I/O가 발생하는 서비스에서는 엄청난 차이를 만드며, 장기적인 관점으로 봤을 때 엄청난 비용 절감을 가져올 수 있다. 하지만 적은 I/O가 발생할 때는 오히려 RDS를 활용하는게 좋을 수 있다. 실제로 오로라의 최소 인스턴스(의 비용은 0.073 USD/h지만, RDS는 0.016USD/h이다. 또, DBMS가 AWS에 의존도가 높아진다는 단점이 존재한다. 결국 모든 기술에는 정답이 없는 만큼 현재 문제 상황에 맞는 데이터베이스를 적절히 고르는게 무엇보다도 중요할 것이다.
###
각주
- 데이터 파일에서 쓰기 작업이란 실제 레코드가 디스크에 존재하는 테이블에 저장된다는 의미입니다.
- 쓰기 연산이란 메모리에서 디스크로 직접 I/O 작업을 진행함을 의미합니다. 여기서 디스크는 SSD가 될 수도 HDD가 될 수 있습니다.
참고
- https://hoing.io/archives/1114
- Real MySQL 1권, InnoDB 스토리지 엔진 구조
- https://dev.mysql.com/doc/refman/8.0/en/innodb-doublewrite-buffer.html
- https://www.youtube.com/watch?v=7_VXMqYixS4
- AWS Reinvent 2021: https://www.youtube.com/watch?v=SEXbvl2oQGs