
Spring bulk Insertion
문제 상황
설문 조사 플랫폼을 만들던 와중에, 질문에 대한 응답 문항과, 응답 문항에 응답할 때 결과들을 insert하는 과정에서 문제가 발생했다. 질문에 상응하는 응답 문항 만큼 insert 쿼리가 날라간다는 점과 응답 문항에 상응하는 점이 문제이다.
question -< answer
- answer을 진행한 만큼 Insert 쿼리가 날라간다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
@DataJpaTest
public class AnswerTest {
@Autowired private SurveyRepository surveyRepository;
@Autowired private AnswerRepository answerRepository;
@Autowired private QuestionRepository questionRepository;
@Test
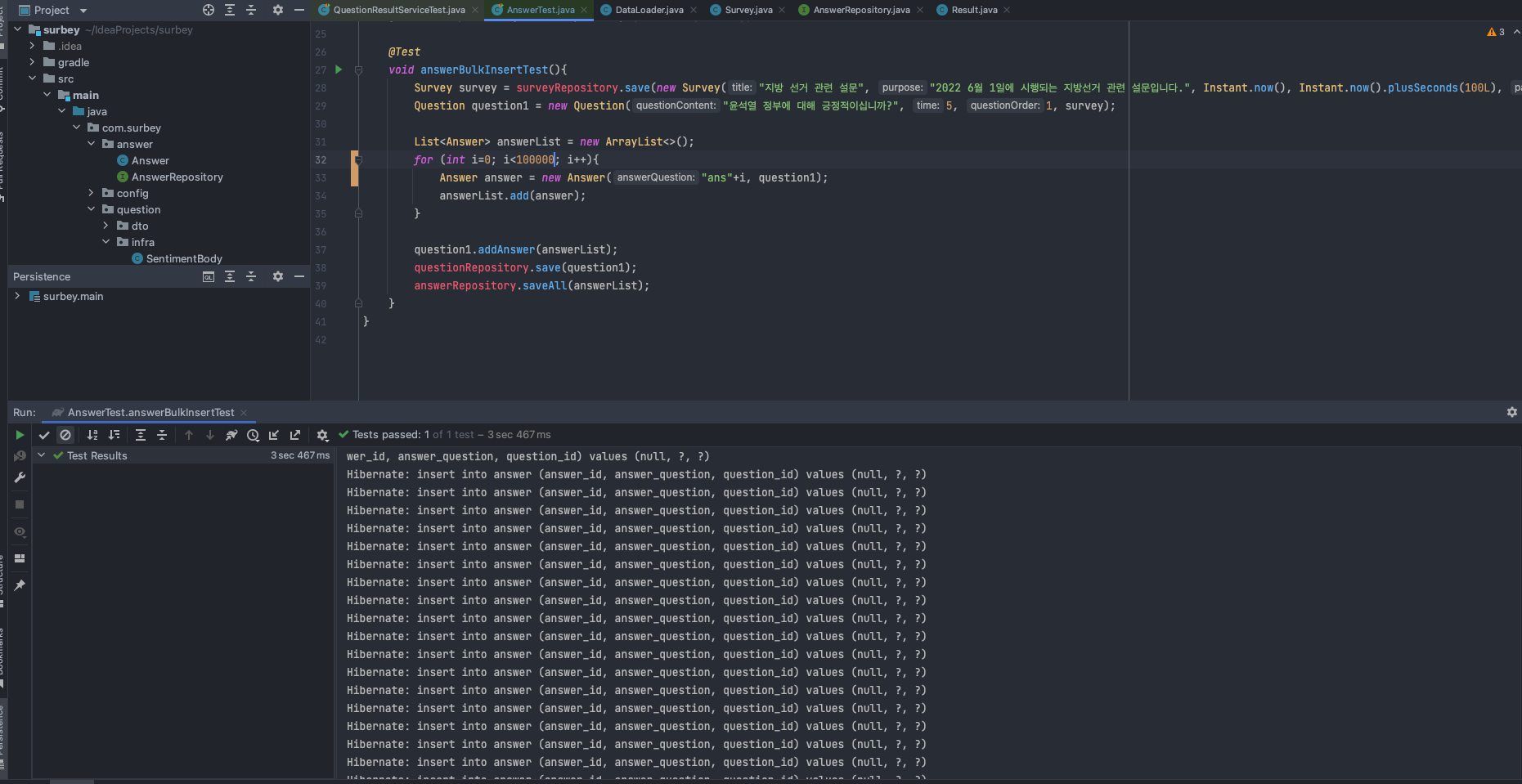
void answerBulkInsertTest(){
Survey survey = surveyRepository.save(new Survey("지방 선거 관련 설문", "2022 6월 1일에 시행되는 지방선거 관련 설문입니다.", Instant.now(), Instant.now().plusSeconds(100L), "pw"));
Question question1 = new Question("윤석열 정부에 대해 긍정적이십니까?", 5, 1, survey);
List<Answer> answerList = new ArrayList<>();
for (int i=0; i<100; i++){
Answer answer = new Answer("ans", question1);
answerList.add(answer);
}
question1.addAnswer(answerList);
questionRepository.save(question1);
answerRepository.saveAll(answerList);
}
}
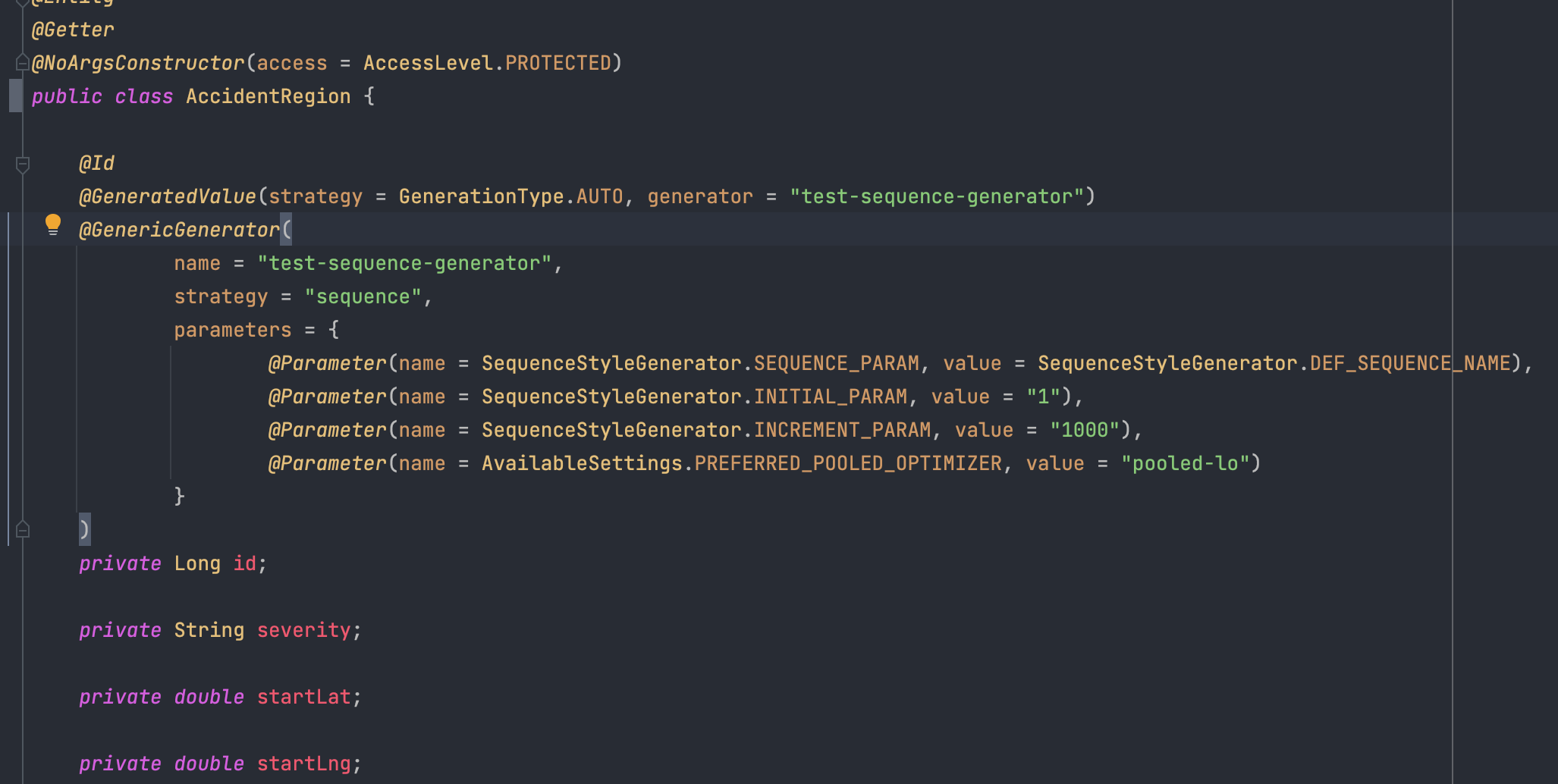
해결책 1 - Spring Data JPA 에서 Batch SEQUENCE 방식을 사용.
- Id 값을 위해 새로운 table를 만들기 때문에 관리 포인트가 늘어난다.
- 이미 사용하는 자동키 전략 방식이 IDENTITY면 변경해야 하는 부담이 생긴다.
- annotation 지정 방식이 매우 번거롭다.
관련해서 실제로 프로젝트를 진행할 때, Navi Project를 진행할 때 Spring DATA JPA를 이용해 5000건 가량의 데이터를 insert했는데 속도도 13초 가량 걸릴 뿐더러 annotation 지정 방식이 굉장히 번거로웠다.

해결책 2 - jdbcTemplate 사용
MySQL Docs에서 many rows에 insert할 때 다음과 같이 조언을 했다.
If you are inserting many rows from the same client at the same time, use
[INSERT]statements with multipleVALUESlists to insert several rows at a time. This is considerably faster (many times faster in some cases) than using separate single-row[INSERT]statements.
다중으로 값을 넣을 예정이라면, 한번에 쿼리로 넣으라는 말이다. 관련해서 구체적인 테스팅은 다음 글을 참고해도 좋을 듯하다.
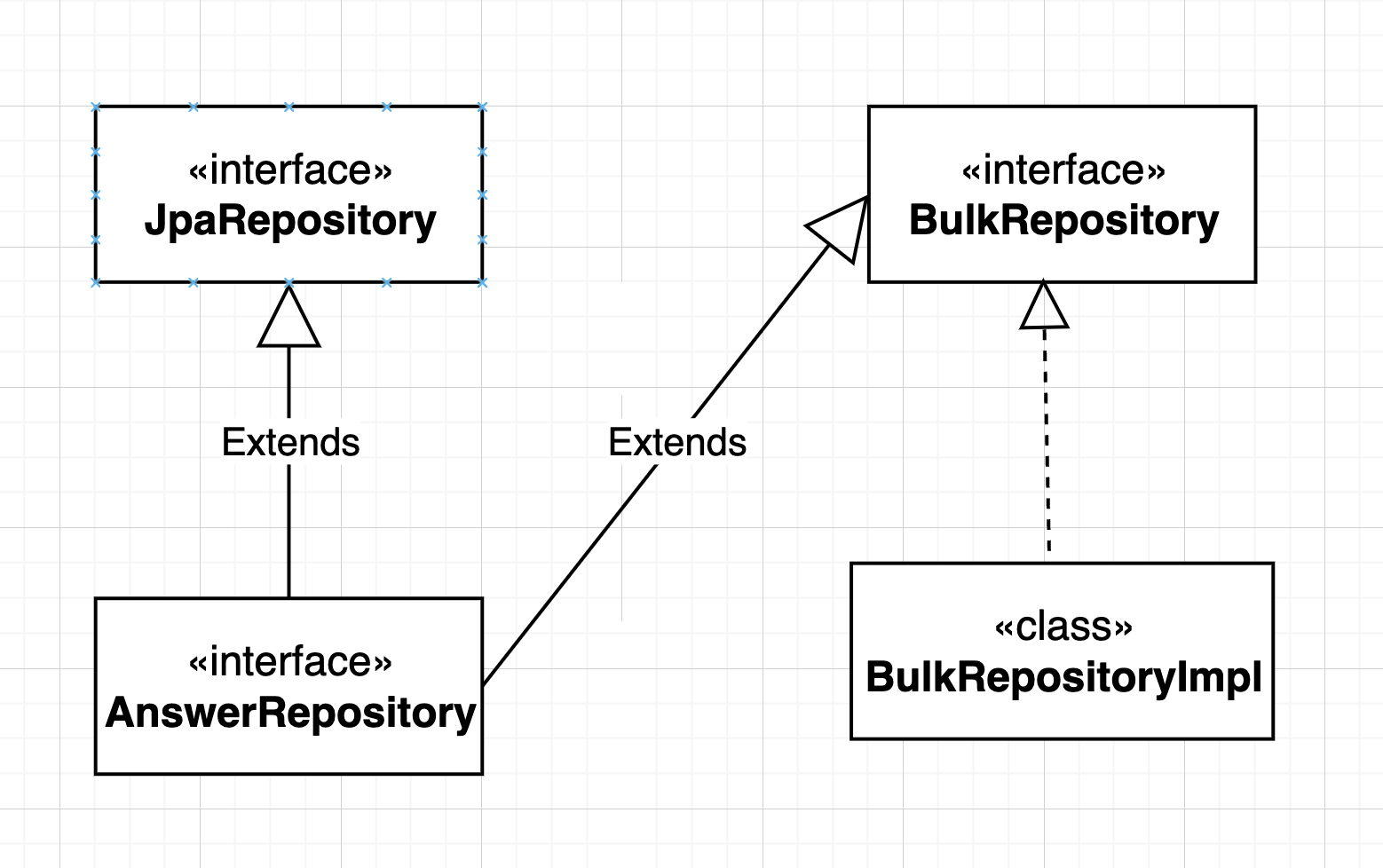
그렇기에 bulk insert에 대한 sql문을로작성할 수 있으면 되는 것이다. 이는 Spirng에 내장된 jdbcTemplate 의 batchUpdate 이용하면 쉽게 bulk insert query를 작성할 수 있었다. Bult insert가 필요한 도메인에 대한 Repository에 공통적으로 사용할 수 있도록 BulkRepository 를 만들고 이에 대한 구현체인 BulkRepositoryImpl를 Bean으로 등록했다.
JdbcTemplate을 이용해 batchUpdate를 통해 batchsize를 100으로 설정하고 Answer 도메인에 대한 query를 날리는 코드는 다음과 같이 구현할 수 있다. .
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Repository
@RequiredArgsConstructor
public class BulkRepositoryImpl implements BulkRepository {
private final JdbcTemplate jdbcTemplate;
@Override
public void answerBatchInsert(List<Answer> answers){
String sql = "INSERT INTO survey_answer"
+ "(answer_question, question_id) values (?, ?)";
jdbcTemplate.batchUpdate(sql, answers, 100, (ps, argument) -> {
ps.setString(1, argument.getAnswerQuestion());
ps.setLong(2, argument.getQuestionId());
});
};
}
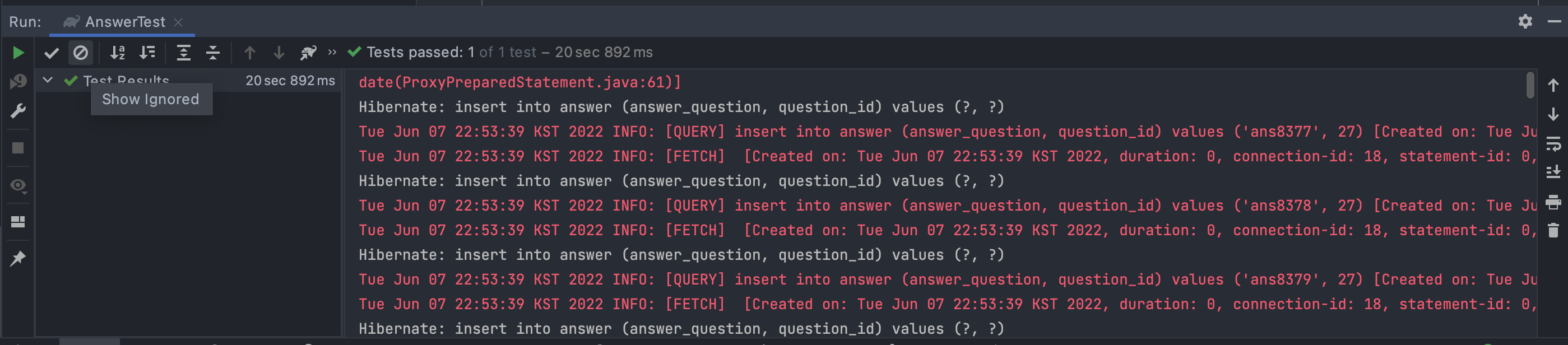
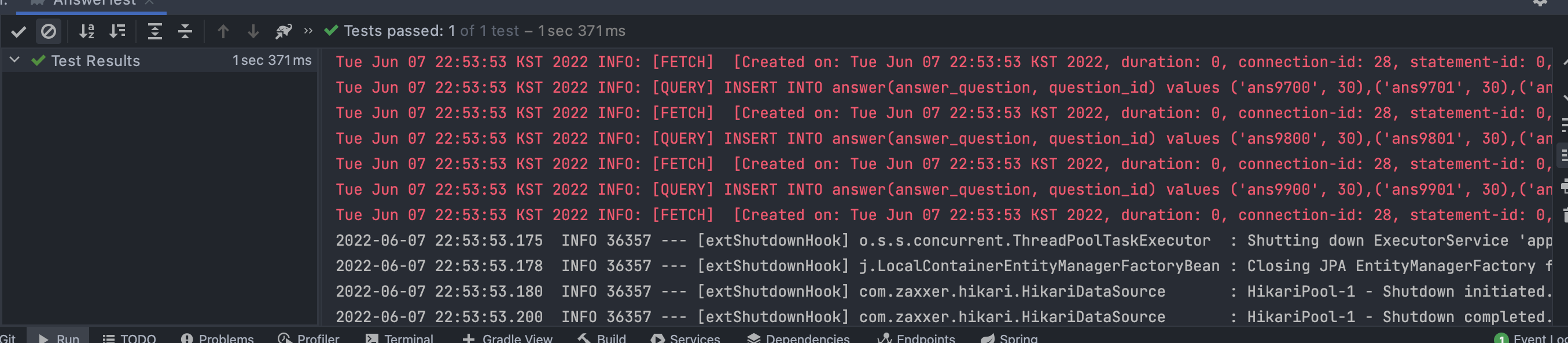
이를 통해 최종적인 성능 비교를 하면 다음과 같다.
- Spring Data JPA의
saveAll()- 20.892초
- JdbcTemplate를 통한 native query - 1.371초
batchsize를 정해준 것은 insert query가 너무 크다면 mysql의 max_allowed_packet 을 초과할 수 있기 때문이다. Mysql8.0은 64MB를 디폴드인 것으로 알고 있으며, 이를 변경할 수 있지만 너무 커지면 세션 당 부하가 커질 수 있다.
만약 Bulk Insert한 것들에 대한 PK(id)값이 필요하다면 다음 글을 참고해보도록 하면 좋을듯 하다.
참고 및 주의사항
- hibernate in-memory DB를 사용하면 성능을 체감하기 어렵다! 꼭 local에서 RDB를 띄워서 진행해보자!
- yml에서 mysql url에
rewriteBatchedStatements=true을 넣어줘야 작동한다!
참고 문헌 및 래포
https://github.com/ChoiEungi/surbey-server
https://sabarada.tistory.com/195
https://kapentaz.github.io/jpa/JPA-Batch-Insert-with-MySQL/#
[https://homoefficio.github.io/2020/01/25/Spring-Data에서-Batch-Insert-최적화/#about](